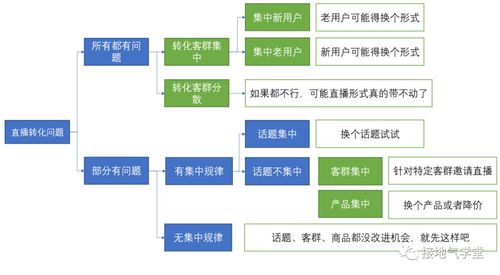
在當今數據驅動的商業環境中,在線數據處理與交易處理業務積累了海量的用戶交互與交易數據。如何從這些數據中挖掘價值,精準識別客戶群體并預測其行為模式,成為企業提升服務效率、優化資源配置的關鍵。本文將初步探討適用于此類業務的兩種核心客戶分群預測模型:交易類模型與循環類模型。
一、 交易類客戶分群預測模型
交易類模型的核心在于分析客戶的離散交易行為。它通常基于RFM(最近一次消費-Recency、消費頻率-Frequency、消費金額-Monetary)框架或其變體進行構建。
- 模型基礎與特征工程:模型輸入特征不僅包括經典的R、F、M指標,還可以融入交易類型(如充值、購買、退款)、交易渠道(APP、網頁、線下)、交易時間偏好、單筆交易金額分布等。對于在線業務,實時性或準實時性的交易流水是特征計算的主要數據源。
- 分群與預測應用:通過聚類算法(如K-Means、DBSCAN)或基于規則的劃分,可以將客戶分為如“高價值活躍客戶”、“近期流失風險客戶”、“低頻高金額客戶”、“沉睡客戶”等群體。預測層面,該模型可用于:
- 價值預測:預測客戶未來一段時間內的消費潛力。
- 流失預警:根據“最近消費時間”的延長和頻率下降,識別可能流失的客戶。
- 交叉銷售:針對特定交易類型的客戶,推薦關聯產品或服務。
- 優勢與挑戰:優勢在于邏輯直觀,與業務KPI(如營收)直接相關,易于解釋和部署。挑戰在于對數據實時性要求高,且主要反映歷史交易結果,對客戶長期生命周期狀態的捕捉可能不足。
二、 循環類客戶分群預測模型
循環類模型側重于識別和預測具有周期性、重復性行為模式的客戶。這在訂閱服務、定期充值、周期性采購等場景中尤為重要。
- 模型基礎與特征工程:此類模型關注行為序列和周期規律。關鍵特征包括:歷史行為序列(如登錄、瀏覽、交易的時間序列)、行為間隔的統計分布(均值、方差)、周期檢測結果(是否存在日、周、月周期)。時間序列分析和序列模式挖掘是特征提取的重要工具。
- 分群與預測應用:可以基于行為周期性和穩定性將客戶分為“強規律型客戶”、“弱規律型客戶”、“隨機型客戶”等。預測應用主要包括:
- 下次行為時間預測:預測客戶下一次登錄、交易或續費的可能時間點,為精準觸達提供時機。
- 周期行為強度預測:預測客戶在下一個周期內的活躍度或交易額。
- 規律中斷預警:當檢測到客戶的規律行為被打破時,觸發干預機制,防止流失。
- 優勢與挑戰:優勢在于能深入理解客戶的行為習慣和生命周期節奏,實現更主動、更及時的服務。挑戰在于模型復雜度較高,需要處理時序數據,且對客戶行為的周期性假設可能不總是成立。
三、 模型融合與業務實踐展望
在實際的在線數據處理與交易處理業務中,交易類模型與循環類模型并非互斥,而是相輔相成。
- 融合策略:可以構建混合特征體系,同時包含交易指標和循環規律指標,進行綜合分群。例如,識別出“高價值且行為規律強”的核心客戶,進行重點維護;或發現“有流失風險但歷史上曾有強周期行為”的客戶,進行針對性召回。
- 工程化考量:模型的成功依賴于穩健的數據管道,能夠低延遲地處理流式交易數據與用戶行為日志,并實時更新客戶特征。模型本身可能需要采用在線學習或定期滾動訓練的方式以適應數據分布的變化。
- 業務閉環:分群與預測的最終目的是驅動行動。模型輸出需要與營銷自動化平臺、客戶服務系統或資源調度系統集成,形成“洞察-決策-行動-反饋”的閉環,持續優化客戶體驗與企業效益。
###
交易類與循環類客戶分群預測模型,為我們理解在線業務中客戶的“價值”與“節奏”提供了有力的雙視角。初步探索表明,結合兩者優勢,構建綜合性的客戶洞察體系,將是提升在線數據處理與交易處理業務智能化水平、實現精細化運營的重要路徑。隨著圖神經網絡、深度時序模型等技術的發展,客戶分群預測的精度與維度有望得到進一步提升。